Build a Scalable, Fault-Tolerant Messaging Cluster on Kubernetes with Apache Kafka and MongoDB
Vikram Vaswani
Apache Kafka is a popular open source tool for real-time publish/subscribe messaging. It uses a scalable, fault-tolerant cluster for message storage, and it can also be integrated with other open source data-oriented solutions such as Apache Hadoop, Apache Spark or Apache HBase for real-time analysis and rendering of streaming data.
Apache Kafka provides a Connect API, which allows external storage systems to be integrated with Kafka. One such example is the MongoDB Kafka Connector, which allows Kafka messages to be stored in MongoDB, or MongoDB data to be published to Kafka. This integration allows users to combine Kafka’s real-time messaging features with the powerful document-oriented data querying capabilities of MongoDB.
Bitnami offers secure and up-to-date Helm charts for Apache Kafka and MongoDB. These charts can be used to deploy and integrate Apache Kafka and MongoDB on Kubernetes, adding improved scalability and reliability and ensuring that the deployments conform to current best practices. This article walks you through the integration.
Assumptions and prerequisites
This article explains the process of integrating Apache Kafka and MongoDB on Kubernetes, such that messages published on Kafka topics are automatically stored as documents in a MongoDB collection using a sink connector. It assumes that:
- You have a Docker environment installed and configured. Learn more about installing Docker.
- You have a Docker Hub account. Register for a free account.
- You have a Kubernetes cluster running with Helm v3.x and kubectl installed. Learn more about getting started with Kubernetes and Helm using different cloud providers.
Step 1: Deploy MongoDB on Kubernetes
Note: If you already have a MongoDB deployment, you can use that instead and skip to Step 2.
The first step is to deploy a MongoDB service on Kubernetes. The simplest way to do this is with Bitnami’s MongoDB Helm chart. Follow the steps below:
-
Add the Bitnami chart repository to Helm:
helm repo add bitnami https://charts.bitnami.com/bitnami -
Execute the following command to deploy MongoDB. Remember to replace the MONGODB-ROOT-PASSWORD placeholder with a custom password for the MongoDB administrator account.
helm install mongodb bitnami/mongodb --set auth.rootPassword=MONGODB-ROOT-PASSWORDWait for a few minutes until the chart is deployed.
-
Use the commands shown in the “Notes” section to create a MongoDB client and connect to the MongoDB service. Remember to replace the MONGODB-ROOT-PASSWORD placeholder with the password defined at deployment time.
kubectl run --namespace default mongodb-client --rm --tty -i --restart='Never' --image docker.io/bitnami/mongodb:4.2.8-debian-10-r39 --command -- bash mongo admin --host "mongodb" --authenticationDatabase admin -u root -p MONGODB-ROOT-PASSWORD -
At the MongoDB command prompt, create a new MongoDB database and user, and grant the user access to the database. The commands below create a new database named mydb and a user account named user with full privileges on that database. Replace the MONGODB-USER-PASSWORD placeholder with a custom password.
use mydb db.createUser( { user: "user", pwd: "MONGODB-USER-PASSWORD", roles: [ { role: "dbOwner", db: "mydb" } ] } ) -
Exit the MongoDB CLI and terminate the client pod.
Step 2: Create and publish a custom MongoDB Kafka Connector image
The next step is to create a container image with the MongoDB Connector for Apache Kafka. This image should also include the Kafka Connect application, which takes care of streaming data between Apache Kafka and other storage systems (such as MongoDB). Follow these steps:
-
Create a file named Dockerfile with the following content:
FROM bitnami/kafka:latest RUN mkdir -p /opt/bitnami/kafka/plugins && \ cd /opt/bitnami/kafka/plugins && \ curl --remote-name --location --silent https://search.maven.org/remotecontent?filepath=org/mongodb/kafka/mongo-kafka-connect/1.2.0/mongo-kafka-connect-1.2.0-all.jar CMD /opt/bitnami/kafka/bin/connect-standalone.sh /opt/bitnami/kafka/config/connect-standalone.properties /opt/bitnami/kafka/config/mongo.propertiesThis Dockerfile uses Bitnami’s Kafka container image as its base image. This is because the Bitnami Kafka container image already contains a working Apache Kafka environment, including the Kafka Connect application and other required dependencies, configuration files and libraries.
After selecting the base image, this Dockerfile performs two main actions:
- It downloads the latest version of the MongoDB Connector for Apache Kafka and adds it to the image.
- It starts the Kafka Connect application in “standalone mode”, passing it a set of configuration files. These files contain the information needed for Kafka Connect to integrate with both Apache Kafka and MongoDB. The files are not included in the image at this point; instead, they will be defined using a Kubernetes ConfigMap in a later step.
Note: At the time of writing, the latest version of the MongoDB Connector for Apache Kafka is v1.2.0. Replace this with the most recent version when using the Dockerfile shown above. You can find the latest version on the project’s GitHub page.
-
Build the image using the command below. Replace the DOCKER-USERNAME placeholder in the command below with your Docker account username.
docker build -t DOCKER-USERNAME/mykafka:1.0 .The result of this command is a Docker image containing Apache Kafka, Kafka Connect, the MongoDB Connector for Apache Kafka and all the related dependencies.
-
Log in to Docker Hub and publish the image. Replace the DOCKER-USERNAME placeholder in the command below with your Docker account username.
docker login docker push DOCKER-USERNAME/mykafka:1.0
Step 3: Deploy Apache Kafka and Kafka Connect on Kubernetes
The next step is to deploy Apache Kafka and the custom Kafka Connect container on Kubernetes. Although you can do this as two separate deployments, an easier way is to combine the two steps into one using the Bitnami Kafka Helm chart. This chart supports an extraDeploy parameter which lets you deploy a set of extra objects with your Apache Kafka deployment.
-
Begin by creating the following values.yml file holding the values that will be supplied to the Helm chart. Replace the KAFKA-USERNAME and KAFKA-PASSWORD with a custom username and password for Kafka client authentication. Replace the DOCKER-USERNAME placeholder with your Docker account username and the MONGODB-USER-PASSWORD placeholder with the password set for the MongoDB user account in Step 1.
auth: clientProtocol: sasl interBrokerProtocol: plaintext jaas: clientUser: KAFKA-USERNAME clientPassword: KAFKA-PASSWORD extraDeploy: |- - apiVersion: apps/v1 kind: Deployment metadata: name: {{ include "kafka.fullname" . }}-connect labels: {{- include "kafka.labels" . | nindent 6 }} app.kubernetes.io/component: connector spec: replicas: 1 selector: matchLabels: {{- include "kafka.matchLabels" . | nindent 8 }} app.kubernetes.io/component: connector template: metadata: labels: {{- include "kafka.labels" . | nindent 10 }} app.kubernetes.io/component: connector spec: containers: - name: connect image: DOCKER-USERNAME/mykafka:1.0 imagePullPolicy: IfNotPresent command: - /bin/bash - -ec - | /opt/bitnami/kafka/bin/connect-standalone.sh /config/connect-standalone.properties /config/mongodb.properties ports: - name: connector containerPort: 8083 volumeMounts: - name: configuration mountPath: /config volumes: - name: configuration configMap: name: {{ include "kafka.fullname" . }}-connect - apiVersion: v1 kind: ConfigMap metadata: name: {{ include "kafka.fullname" . }}-connect labels: {{- include "kafka.labels" . | nindent 6 }} app.kubernetes.io/component: connector data: connect-standalone.properties: |- bootstrap.servers = {{ include "kafka.fullname" . }}-0.{{ include "kafka.fullname" . }}-headless.{{ .Release.Namespace }}.svc.{{ .Values.clusterDomain }}:{{ .Values.service.port }} key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=true offset.storage.file.filename=/tmp/connect.offsets offset.flush.interval.ms=10000 plugin.path=/opt/bitnami/kafka/plugins sasl.mechanism=PLAIN security.protocol=SASL_PLAINTEXT sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \ username="KAFKA-USERNAME" \ password="KAFKA-PASSWORD"; consumer.sasl.mechanism=PLAIN consumer.security.protocol=SASL_PLAINTEXT consumer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \ username="KAFKA-USERNAME" \ password="KAFKA-PASSWORD"; mongodb.properties: |- connection.uri=mongodb://user:MONGODB-ROOT-PASSWORD@mongodb.default.svc.cluster.local:27017/mydb name=mongo-sink topics=mytopic connector.class=com.mongodb.kafka.connect.MongoSinkConnector tasks.max=1 key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=false value.converter.schemas.enable=false database=mydb collection=sink - apiVersion: v1 kind: Service metadata: name: {{ include "kafka.fullname" . }}-connect labels: {{- include "kafka.labels" . | nindent 6 }} app.kubernetes.io/component: connector spec: ports: - protocol: TCP port: 8083 targetPort: connector selector: {{- include "kafka.matchLabels" . | nindent 6 }} app.kubernetes.io/component: connectorThis file contains a lot of information, so let’s step through it in detail:
- The auth parameters define the protocol that Kafka will use for client and inter-broker communication. It also specifies the username and password for JAAS-based client authentication.
- The extraDeploy parameter creates an additional deployment using the custom Kafka Connect image created in Step 2. It also mounts a configuration volume at the /config mount point. This volume will hold the configuration files for Kafka Connect.
- The file defines an additional ConfigMap which is mounted at /config and holds two minimal configuration files:
- The connect-standalone.properties file defines the standalone mode configuration for Kafka Connect. It specifies the host name of the Apache Kafka server and the client credentials to use when connecting to it. It also tells Kafka Connect which converter to use (JSON) when serializing messages for MongoDB.
- The mongodb.properties file contains additional configuration for the MongoDB sink connector. This configuration includes the MongoDB connection URI, database and collection to use for the saved messages. It also specifies the converter to use for the data (JSON again). In particular, note the topics parameter, which specifies the list of topics to monitor/save in MongoDB.
Find additional properties to control how data is handled by the sink connector in the official Kafka Sink Connector documentation.
-
Once the configuration file has been created, deploy Apache Kafka on Kubernetes using the Helm chart:
helm install kafka bitnami/kafka -f values.ymlWait for a few minutes until the chart is deployed.
-
Confirm that the Apache Kafka and Kafka Connect pods are running:
kubectl get podsYou should see something like the output below:
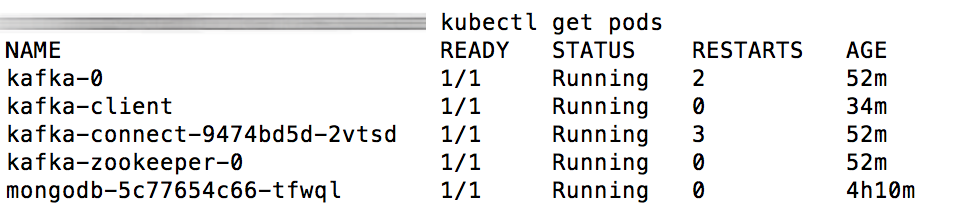
Step 4: Test the integration
You can now proceed to test the integration, by publishing messages to the Apache Kafka topic mytopic and then checking if the messages were streamed and saved to MongoDB. Follow the steps below:
-
Create a kafka_jaas.conf file with the content below. Replace the KAFKA-USER and KAFKA-PASSWORD placeholders with the values used in Step 3.
KafkaClient { org.apache.kafka.common.security.plain.PlainLoginModule required username="KAFKA-USER" password="KAFKA-PASSWORD"; }; -
Create a client.properties file with the content below:
security.protocol=SASL_PLAINTEXT sasl.mechanism=PLAIN -
Create an Apache Kafka client pod and copy the files above to it:
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:2.5.0-debian-10-r96 --namespace default --command -- sleep infinity kubectl cp --namespace default client.properties kafka-client:/tmp/client.properties kubectl cp --namespace default kafka_jaas.conf kafka-client:/tmp/kafka_jaas.conf -
Log in to the Apache Kafka client pod console:
kubectl exec --tty -i kafka-client --namespace default -- bash export KAFKA_OPTS="-Djava.security.auth.login.config=/tmp/kafka_jaas.conf" -
At the pod console, publish one or more messages to the mytopic topic. Ensure that the messages are formatted in JSON, as shown in the example below.
kafka-console-producer.sh --producer.config /tmp/client.properties --broker-list kafka-0.kafka-headless.default.svc.cluster.local:9092 --topic mytopic {"hello":"world"} {"foo":"bar"} -
Exit the Apache Kafka client pod.
-
Create a new MongoDB client pod:
kubectl run --namespace default mongodb-client --rm --tty -i --restart='Never' --image docker.io/bitnami/mongodb:4.2.8-debian-10-r39 --command -- bash -
At the MongoDB client pod console, log in to the MongoDB client pod using the user account credentials defined in Step 1:
mongo admin --host "mongodb" --authenticationDatabase mydb -u user -p MONGODB-USER-PASSWORD -
Confirm that the messages sent previously are saved in the sink collection in the mydb database:
use mydb db.sink.find()You should see the output below:
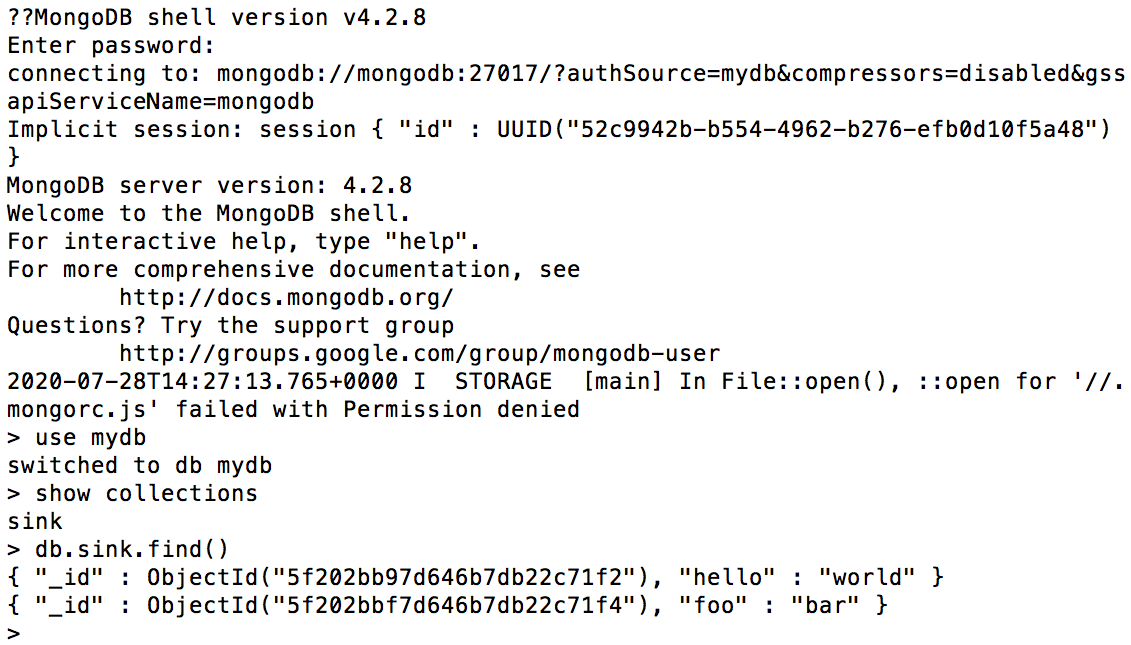
At this point, the integration between Apache Kafka and MongoDB is complete. Messages sent to specified topics in Apache Kafka will be automatically transferred and saved in MongoDB, where they can be further queried, analyzed or modified.
Useful links
To learn more about the topics discussed in this guide, use the links below:
- Bitnami Apache Kafka Helm chart
- Bitnami MongoDB Helm chart
- Apache Kafka Connect API
- MongoDB Kafka Sink Connector guide